Performanz von Prüfsummenverfahren
In Linux-Betriebssystemen werden standardmäßig mehrere Programme zur Erstellung von Prüfsummen bereitgestellt. (sum, cksum, md5sum, sha1sum, sha224sum, sha256sum, sha384sum, sha512sum)
Je nach Verwendungszweck kommen unterschiedliche Verfahren in Betracht. Bei den kryptographischen Hashfunktionen gibt es Abstufungen hinsichtlich der Sicherheit. Kommt es nur auf die Überprüfung von Dateien hinsichtlich Korruption und nicht auch Manipulation an, hat man grundsätzlich die freie Auswahl. Für die Performanz automatisierter Abläufe ist die erforderliche Rechenzeit ein Kriterium bei der Auswahl des Prüfsummenverfahrens.
Grundsätzliche Dauer der Berechnung
Die Rechendauer ist vom Prozessor und der Betriebssystemarchitektur abhängig. Nicht so sehr fällt die kryptologische Sicherheit ins Gewicht. So ist md5sum beispielsweise schneller als der CRC-Algorithmus von cksum. Je nachdem, ob ein 32-Bit- oder 64-Bit-Betriebssystem verwendet wird, ändern sich fast alle Relationen bis zur Reihenfolge maßgeblich. Auf 64-Bit-Systemen ist sha512sum / sha384sum entgegen teilweise anderer Aussagen1 zumeist schneller als sha256sum / sha224sum.2 Auf 32-Bit-Systemen hingegen braucht sha512sum / sha384sum sehr markant länger als alle anderen Verfahren.
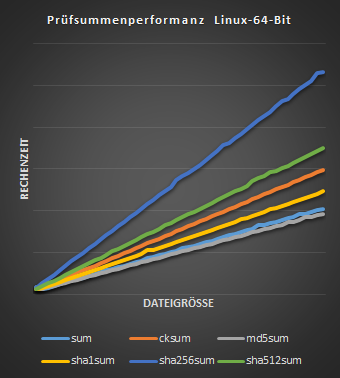
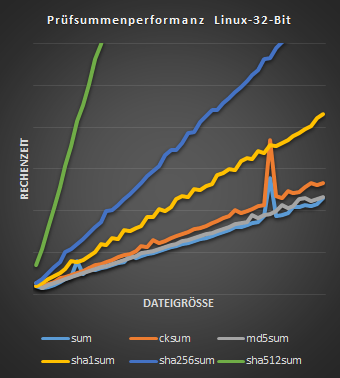
Relevanz des Arbeitsspeichers
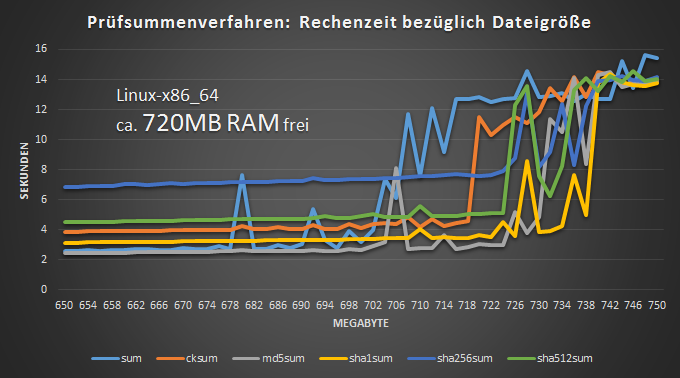
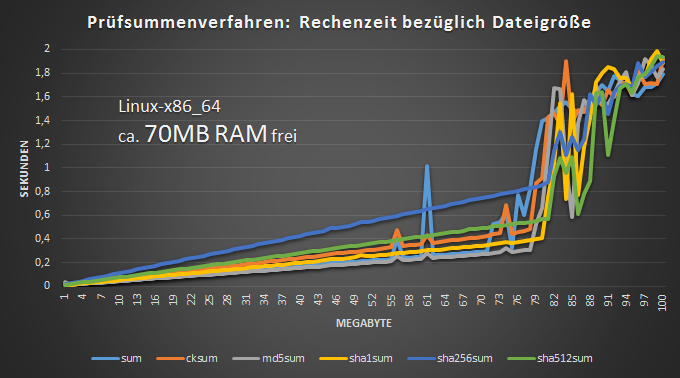
Äußerst problematisch ist der Arbeitsspeicher (RAM) bei der Zeitplanung. Auf eine unbefriedigende Art kann der verfügbare Arbeitsspeicher die Auswahl des passenden Hashverfahrens erleichtern. Bei der Betrachtung der Rechenzeit bezüglich der Größe der zu prüfenden Datei kommt der Punkt, an dem plötzlich alle Prüfsummenverfahren etwa gleich lang brauchen. Ein Zeitvorteil von beispielsweise sum vor sha256sum ist nicht gegeben. Jede Auswahl von möglichst performanten Hashfunktionen ist praktisch hinfällig, wenn die untersuchte Dateigröße etwa dem frei verfügbaren Arbeitsspeicher entspricht oder ihn übersteigt. Überwiegt der Anteil solch großer Dateien bei der geplanten Anwendung, könnte also gleich zu einer aktuell als äußerst manipulationssicher geltenden Prüfsumme gegriffen werden, auch wenn technisch nur zufällige Veränderungen bei der Datenübertragung ausgeschlossen werden sollen.
Das Diagramm zeigt vergleichend unterschiedliche Prüfsummenverfahren hinsichtlich der Rechenzeit in Bezug auf die Dateigröße. Erkennbar ist das Phänomen im Bereich der gänzlichen Ausnutzung des Arbeitsspeichers. Hier bei etwa 720MB freiem RAM:
Vergleichend wurde der Arbeitsspeicher durch Erstellung einer RAM-Disk (sudo mount -t ramfs ramfs /media/ramdisk) vor der Messung gefüllt, bis hier nur noch etwa 70MB RAM für die Rechenfunktion frei standen:
Messverfahren
Zur Messung der Berechnungszeit der einzelnen Prüfsummenprogramme kamen folgende Python-Skripte zum Einsatz.
Zur Betrachtung einer einzelnen Datei:
# 19.01.2015
# Helge Brunkhorst
# hashtime.py V03
# Vergleich des Zeitaufwandes unterschiedlicher Pruefsummenverfahren
import platform
if platform.system() != "Linux":
print("Dieses Programm ist leider nur fuer Linux-Betriebssysteme geeignet!")
exit()
try:
input = raw_input
except NameError:
pass
import subprocess
import time
import sys
import os
hashmethoden = ["sum", "cksum", "md5sum", "sha1sum", "sha224sum", "sha256sum", "sha384sum", "sha512sum"]
wiederholungen = 1
bericht = "\nZusammenfassung\n"
maximalmethodenzeichenzahl = 0
for methode in hashmethoden:
if len(methode) > maximalmethodenzeichenzahl:
maximalmethodenzeichenzahl = len(methode)
print("\nEs wird die Zeit ermittelt, die fuer die Erstellung unterschiedlicher Pruefsummen erforderlich ist.")
if len(sys.argv) > 1:
testdatei = sys.argv[1]
else:
print("\nSie muessen eine Datei angeben, fuer die Pruefsummen erstellt werden sollen!")
print("\nEs ist moeglich, gleich beim Programmaufruf einen DATEINAMEn als Kommandozeilenargument anzugeben.\nBeispiel:~$ python " + sys.argv[0] + " DATEINAME")
i = input("\nSie koennen jetzt einen Dateipfad angeben (Ohne Eingabe wird das Programm durch ENTER beendet.):\n> ")
if i != "":
testdatei = i
else:
exit()
if len(sys.argv) > 2:
wiederholungen = int(sys.argv[2])
else:
print("\nEs ist moeglich, beim Programmaufruf die gewuenschte Anzahl der DurchlaufWIEDERHOLUNGEN als Kommandozeilenargument anzugeben.\nBeispiel:~$ python " + sys.argv[0] + " DATEINAME WIEDERHOLUNGEN")
i = input("\nSie koennen jetzt die Anzahl der Durchlaeufe bestimmen (Ohne Eingabe wird durch ENTER ein einzelner Durchlauf gestartet.):\n> ")
if i != "":
wiederholungen = int(i)
print("\nFuer den Test wird folgende Datei verwendet:\n" + testdatei)
print("\nEs werden nacheinander folgende Programme ausgefuehrt:\n" + ", ".join(hashmethoden))
print("\nJeder Programmdurchlauf wird mit folgender Anzahl wiederholt:\n" + str(wiederholungen))
for methode in hashmethoden:
for x in range(1, wiederholungen + 1):
print("\nGestartetes Programm: " + methode + " (" + str(x) + ". Durchlauf)")
t1 = time.time()
subprocess.call([methode, testdatei])
t2 = time.time()
t = t2 - t1
print("Verstrichene Sekunden: " + str(t))
leerzeichen = " "
while len(methode) + len(leerzeichen) != maximalmethodenzeichenzahl + 1:
leerzeichen = leerzeichen + " "
bericht = bericht + "\n" + methode + leerzeichen + str(t) + " s"
print("#############################################")
print(bericht)
print("\nDatei: " + testdatei)
print("Groesse: " + str(os.stat(testdatei).st_size) + " B")
print("\nplatform: " + platform.platform())
print("machine: " + platform.machine())
print("processor: " + platform.processor())
print("\nComputername: " + platform.node())
print("\n#############################################")
Zur Generierung automatischer Dummy-Dateien für die Betrachtung der Abhängigkeit von der Dateigröße:
# 20.01.2015
# Helge Brunkhorst
# hashtimetable.py V03
import platform
if platform.system() != "Linux":
print("Dieses Programm ist leider nur fuer Linux-Betriebssysteme geeignet!")
exit()
# Kompatibilitaet von input() zu python2 herstellen:
try:
input = raw_input
except NameError:
pass
import time
import subprocess
import datetime
hashmethoden = ["sum", "cksum", "md5sum", "sha1sum", "sha256sum", "sha512sum"]
bericht = "MiB;" + ";".join(hashmethoden) + "\n"
print("Dieses Programm erstellt Dummy-Dateien und misst die Zeit, die fuer die Erstellung von Pruefsummen mit md5sum und sha512sum erforderlich ist. Der Groessenbereich der Dummy-Dateien und die Groesse der Zwischenstufen koennen gewaehlt werden. Endlich wird eine Tabelle mit den Messergebnissen im CSV-Format gespeichert. Dateien werden unter dem aktuellen Pfad erstellt, aus dem dieses Skript aufgerufen wurde.")
start = int(input(">>> Kleinste Dummy-Datei in MiB: "))
stop = int(input(">>> Groesste Dummy-Datei in MiB: ")) + 1
step = int(input(">>> Zwischenschritte in MiB: "))
for megabyte in range(start, stop, step):
hashzeiten = []
testdatei = "dummy_"+str(megabyte)+"M.txt"
aufruf = ["dd", "if=/dev/urandom", "of="+testdatei, "bs=M", "count="+str(megabyte)]
print(">>> " + " ".join(aufruf))
subprocess.call(aufruf)
for methode in hashmethoden:
aufruf = [methode, testdatei]
print(">>> " + " ".join(aufruf))
t1 = time.time()
subprocess.call(aufruf)
t2 = time.time()
t = t2 - t1
hashzeiten.append(str(t).replace(".",","))
aufruf = ["rm", testdatei]
print(">>> " + " ".join(aufruf))
subprocess.call(aufruf)
zwischenbericht = str(megabyte) + ";" + ";".join(hashzeiten)
print(">>> " + zwischenbericht.replace(";","\t"))
bericht = bericht + zwischenbericht + "\n"
dateiname = "hashtimetable_" + datetime.datetime.now().strftime("%Y%m%d_%H%M%S") + ".csv"
datei = open(dateiname, "w")
datei.write(bericht)
datei.close()
print(">>> Der Bericht wurde als " + dateiname + " gespeichert.")